-
데이터 전처리 (Data preprocessing)Machine learning 2024. 2. 7. 01:38데이터를 분석 및 처리에 적합하게 만드는 과정, 또는 Raw data를 모델 학습에 맞게 변형하는 과정이다.대략 4가지 과정이 포함된다. (정의가 제각각)
- 데이터 수집: 데이터 수집 과정 구축
- 데이터 정제: 이상치, 노이즈, 결측치 처리
- 데이터 통합: 다양한 Source에서 입력되는 데이터 통합
- 변수 처리: 불필요한 변수 제거, 파생 변수 생성, 정규화 등
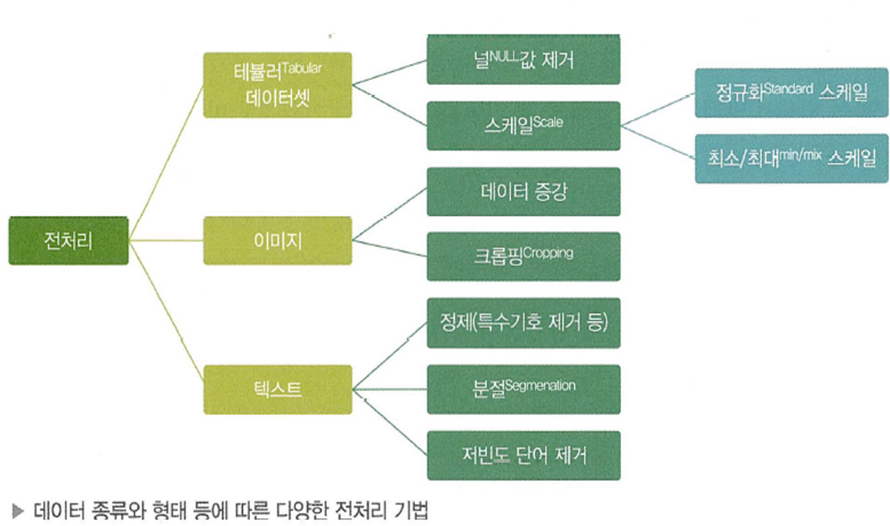 대표적인 전처리에는 이상치 처리, 결측치 처리, 특성 스케일링(정규화,표준화)가 있다.1. 이상치 처리이상치는 정상적인 데이터 분포에서 지나치게 멀리 떨어져 있는 소수의 데이터를 의미한다.전체 데이터의 일반적인 패턴을 학습해야 하는 모델 입장에서는 노이즈와 같으므로 제거가 필요하다. 제거하지 않으면, 이상치의 영향을 받아 모델의 예측 성능이 떨어질 수 있다.이상치에 대한 경계는 도메인 지식에 따라 정해지거나, 상자그림이나 분포를 통해 정해질 수 있다.보통 이상치는 제거한다.
대표적인 전처리에는 이상치 처리, 결측치 처리, 특성 스케일링(정규화,표준화)가 있다.1. 이상치 처리이상치는 정상적인 데이터 분포에서 지나치게 멀리 떨어져 있는 소수의 데이터를 의미한다.전체 데이터의 일반적인 패턴을 학습해야 하는 모델 입장에서는 노이즈와 같으므로 제거가 필요하다. 제거하지 않으면, 이상치의 영향을 받아 모델의 예측 성능이 떨어질 수 있다.이상치에 대한 경계는 도메인 지식에 따라 정해지거나, 상자그림이나 분포를 통해 정해질 수 있다.보통 이상치는 제거한다.
상자그림 예시 
이상치 처리 전(왼)과 후(오)의 분포 변화 시각화 2. 결측치 처리
결측치는 값이 존재하지 않는 데이터를 의미한다.결측치가 있는 행 전체를 제거하기도 하나, 정보 손실을 최소화 하기위해 여러가지 방법으로 결측치를 보간, 즉 특정 값으로 대체한다.처리 방법은 아래와 같이 다양하다.- 행,열 제거: 결측치가 있는 행,열 전체를 제거
- 새로운 범주 생성: 범주형 변수는 결측치를 ‘누락된 값’이라는 새로운 범주로 변경 가능
- 값이 결측된 특정한 이유(패턴)이 있다고 판단될 때 사용
- 임의의 값 보간: 정상 데이터에 있을 수 없는 임의의 값을 입력
- 대표값으로 보간: 평균, 중간값 등
- 선형 보간: 앞뒤 행의 값에 선형으로 비례하는 값으로 보간 (보통 시계열 데이터에 사용)
- 도메인 정보 활용: 도메인 정보를 활용해 특정 값 입력
상황에 따라 위의 방법 혹은 기타 방법을 취사선택하면 된다.
Pandas를 사용한다면 관련 메서드로 간편하게 결측치 처리가 가능하다.
- Dropna(): 결측 행 혹은 열 제거
- fillna(): 결측치를 특정 값으로 대체
- Interpolate: 선형 보간 등
3. 특성 스케일링(Feature Scaling)
트리 기반 모델을 제외한 대부분의 모델(회귀 모델 등)은 학습 및 예측에 있어 변수의 스케일에 영향을 받는다.
예를 들어, X1의 범위가 (0-1), X2의 범위가 (-100,100)이라면 모델 학습 과정에서 X2의 영향도가 더 커질 수 있다.
특히 딥러닝 모델은 비교적 큰 값이나 균일하지 않은 데이터(변수의 스케일이 제각각인 경우)를 주입하면, Gradient가 커져 네트워크가 수렴하는 것을 방해하게 된다.네트워크를 쉽게 학습시키려면 아래 특징을 따라야 한다.- 작은 값을 취함: 대부분의 값이 0-1 사이여야 함
- 균일해야 함: 모든 특성이 대체로 비슷한 범위를 가짐
따라서 변수를 일정한 작은 범위(보통 0-1 사이)로 변환하는 Scaling 작업이 필요하다.
특성 스케일링은 종류에 따라 정규화(Normalization), 표준화(Standardization)으로 나뉜다.3-1) 정규화(Normalization)- 값의 범위를 0-1 사이의 값으로 변환하며 MinMaxScaler가 대표적이다.
- 분포의 형태는 유지하고, 값의 크기만 0-1 사이로 변환된다.
3-2) 표준화(Standardization)- 값의 범위를 평균 0, 분산 1이 되도록 변환하며, StandardScaler가 대표적이다.
- 정규분포로 변환됨
- Scikit-learn을 통해 쉽게 변환 가능
sklearn.preprocessing에서 다양한 Scaler를 불러올 수 있다.- MinMaxScaler, StandardScaler, MaxAbsScaler, RobustScaler 등 존재

MinMaxScaler 공식 
StandardScaler 공식 
Scaling 방식에 따른 데이터 차이 참고자료
1. 김기현의 딥러닝 부트캠프
'Machine learning' 카테고리의 다른 글
Decision Tree (0) 2024.02.08 서포트 벡터 머신(Support Vector Machine, SVM) (0) 2024.02.07 탐색적 데이터 분석(Exploratory data analysis, EDA) 알아보기 (0) 2024.02.07